| |
| (1) |
ベンダープレゼンテーション内容
|
| |
将来の超高速計算機(2010年代前半頃・1ペタフロップス超を想定)に必要な要素技術の研究開発を中心に、HPCベンダーにてHPCハードウェア開発の動向についてプレゼンテーションを実施。
特に、マルチスケール・マルチフィジックス (超大規模・複雑)なシミュレーションを実現するスペックと、それを達成するためのハードウェア上のブレークスルーを明らかにすることに主眼を置いたプレゼンテーションを求めた。 (超大規模・複雑)なシミュレーションを実現するスペックと、それを達成するためのハードウェア上のブレークスルーを明らかにすることに主眼を置いたプレゼンテーションを求めた。
 |
 |
 |
 |
|
|
|
マルチスケール |
: |
ミクロからマクロまで異なるスケール |
| |
|
マルチフィジックス |
: |
異なる物理現象・状態 |
|
|
|
 |
|
 |
|
|
| (2) |
プレゼンテーション実施者
|
| |
第1回ワーキンググループでは、国内でHPC製品を開発しているベンダー3社(日立製作所、富士通、日本電気)がプレゼンテーションを実施した。
第2回ワーキンググループでは、海外HPCベンダーを代表して、Intelがプレゼンテーションを実施した。 |
|
|
| (3) |
プレゼンテーション項目 |
| |
 将来の超高速計算機システムについて 将来の超高速計算機システムについて
| |
・ハードウェア(CPU、メモリ、インターコネクト、I/O等)
・ソフトウェア(OS、プログラミング言語、開発ツール等)
・システム(プロセッサ数、高信頼化機能等)
・性能(理論性能、実効性能) |
|
 アプリケーションソフトウェアについて アプリケーションソフトウェアについて |
 必要な要素技術について 必要な要素技術について |
| |
・現在の技術の限界と、期待されるブレークスルー
・大学等を含む、研究開発の現状
・ブレークスルーに向けた研究開発内容
・実現する技術の適用分野(超高速計算機以外の適用分野を含む) |
|
 要素技術の研究開発について 要素技術の研究開発について |
|
|
| (4) |
プレゼンテーションの概要
|
| |
|
将来の超高速計算機システムについて
|
| |
1ペタフロップス超の実効性能実現のために想定されるシステムは、数ギガフロップスのCPUが数百万個で構成されるシステムから、数十〜数百ギガフロップスのCPUが数万〜数十万個で構成されるシステム、更には、数テラフロップスのCPUが数千個で構成されるシステムまで、幅広いシステム構成が考えられている。
この中で、各社共通のターゲットシステムとしては、以下のような構成が挙げられた。
| |
| ・単体CPU性能(総CPU数) |
: |
数十ギガフロップス(数十万個)〜数百ギガフロップス(数万個) |
| ・総メモリ容量 |
: |
数百テラバイト |
| ・CPU−メモリ間伝送速度 |
: |
10〜20ギガ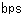  シグナル以上 シグナル以上 |
| ・ノード間伝送速度 |
: |
20〜40ギガシグナル以上 |
| ・消費電力 |
: |
CPUあたり200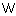 以下 以下 |
|
|
また、計算機のアーキテクチャとしては、ターゲットとするアプリケーションを見極めた上で、これに適したアーキテクチャを検討すべきとの意見があった。
|
|
アプリケーションソフトウェアについて
|
| |
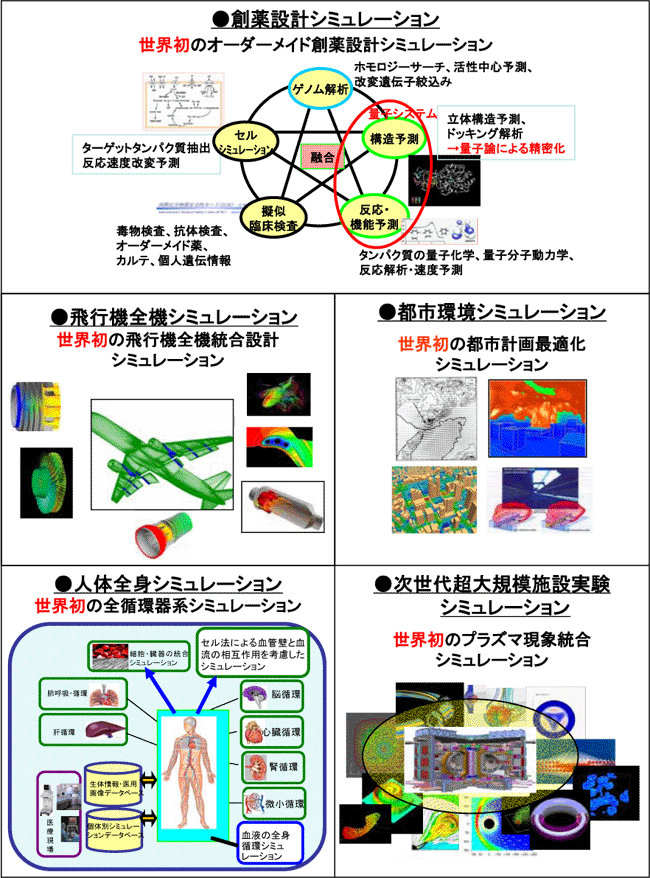
マルチスケール・マルチフィジックスなシミュレーションの実現には、 で挙げられたような実効性能で1ペタフロップス超の超高速計算機システムが必要とされている。 で挙げられたような実効性能で1ペタフロップス超の超高速計算機システムが必要とされている。
マルチスケール・マルチフィジックスなシミュレーションの例としては、薬剤効果に関するDNAから各器官で構成される人体までの一貫した解析や、原子炉材料破壊に関する原子レベルの結合破壊から目に見える破壊まで一貫した解析などが挙げられた。
このようなマルチスケール・マルチフィジックスなシミュレーションとして、想定し得るイメージ図を例示すると、例えば次項のものが挙げられる。
| |
また、各アプリケーション分野で、以下の様な経済的な波及効果が挙げられた。
| ・ナノテク分野 |
: |
半導体業界、ディスプレイ業界の国際競争力の向上
ストレージ装置のユビキタス化、国際競争力の向上 |
| ・バイオ分野 |
: |
医薬品業界の国際競争力の向上 |
| ・流体・構造分野 |
: |
製造業全体の国際競争力の向上
エネルギー・環境社会インフラの高度化、国際競争力の向上 |
| ・気象分野 |
: |
都市の安全性向上、エネルギー需要・環境コストの長期的予測 |
|
|
| <マルチスケール・マルチフィジックスなシミュレーションのイメージ図> |
 |
| |
|
| (注) |
あくまでも事務局が作成した例示であり、各アプリケーション分野においての詳細な議論は、今後のワーキンググループにおいてそれぞれのスーパーコンピュータユーザ機関から説明を求めた上で、別途取りまとめることとする。
|
|
|
|
|
半導体微細加工技術について
|
| |
これまでのスーパーコンピュータの性能向上は、半導体微細加工技術の進歩に負うところが大であり、その法則性は「ムーアの法則」として知られている。
|
|
|
|
|
|
|
ムーアの法則 |
: |
米Intelの設立者の一人であるゴードン・ムーア(Gordon E. Moore)が経験則として提唱した、「半導体の集積密度は24ヶ月で倍増する」という法則。これから転じて、「CPUの性能は24カ月で2倍になる」とも言われる。 |
|
|
|
|
|
|
半導体業界がまとめた半導体技術ロードマップITRS(International Technology Roadmap for Semiconductors)の最新版では、2010年時点のLSIの製造技術として45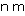 プロセスの実現が予測されている。 プロセスの実現が予測されている。
これに対して、今回プレゼンテーションを実施したIntelでは、ITRSを前倒しし、2007年に45プロセス、2010年には32プロセスの実現を目指すとしている。
Intelによれば、従来型の半導体微細加工技術のままではスーパーコンピュータの性能向上における寄与度が今後徐々に低下するものと予測している。今回、Intel(2010年32プロセス)及び国内ベンダー(2010年45プロセス)のいずれの計画においても、将来の超高速計算機を開発する上で、次の項目 に挙げるとおり、ブレークスルーを要する技術課題が存在することが明らかとなった。 に挙げるとおり、ブレークスルーを要する技術課題が存在することが明らかとなった。
|
|
|
|
ブレークスルーが必要な要素技術について
|
| |
超高速計算機システムを実現するために、技術的なブレークスルーが必要で、特に重点的に研究開発が必要なハードウェアの要素技術について、以下のような項目が挙げられた。
CPUの高速化
半導体微細加工技術が進むなか、リーク電流により消費電力が増大し、結果としてCPUの高速化が阻害されると予測されている。
|
|
|
|
|
|
|
リーク電流 |
: |
半導体が動作していない場合でも不要に流れてしまう電流。
半導体の微細化が進むほど、大きくなる傾向にある。 |
|
|
|
|
|
|
この問題を解消するために必要なブレークスルーとして、消費電力を増加させないデバイス高速化手法の開発や、冷却能力の向上等が挙げられた。
また、数百ギガフロップスの単体CPU性能を実現するためには、プロセッサに関するハイレベルなアーキテクチャの検討が必要との意見があった。
これらの技術の波及効果として、高性能サーバ、ネットワーク機器、画像処理システム、PC、デジタル家電等への適用が考えられている。
|
CPU−メモリ間伝送速度の高速化
既存の電気伝送技術では、CPU−メモリ間伝送速度は、多信号、数十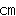 程度の伝送では5〜10ギガ程度が高速化の限界であるとされている。 程度の伝送では5〜10ギガ程度が高速化の限界であるとされている。
この問題を解消するために必要なブレークスルーとして、光伝送技術の開発等が挙げられた。
この技術の波及効果として、高性能サーバ、ネットワーク機器、画像処理システム、ファイル装置、PC、デジタル家電、医療機器、車/航空機用機器等への適用が考えられている。
|
ノード間伝送速度の高速化
超高速計算機システムの実現には、多数のノードを接続する大規模並列システムが不可欠であり、システム全体の実行性能向上には、更なるノード間伝送速度の向上が必要であるとされている。
要求性能を実現するために必要なブレークスルーとして、光多重伝送技術の開発や高速スイッチ技術の開発等が挙げられた。
また、システムの高速化のためには、CPU性能とノード間伝送速度のバランスが大事であるとの意見があった。
これらの技術の波及効果として、高性能サーバ、ネットワーク機器、医療機器等への適用が考えられている。
|
低消費電力化
リーク電流による消費電力増大などにより、既存技術の延長では、1CPUあたり500程度の高消費電力になるとされている。
この問題を解消するために必要なブレークスルーとして、リーク電流を低減するための低消費電力化技術の開発等が挙げられた。
また、CPUあたりの低消費電力化と共に、メモリの低消費電力化や、既存の空冷技術に代わる液冷を採用した小型冷却技術の開発が必要との意見があった。
これらの技術の波及効果として、高性能サーバ、ネットワーク機器、画像処理システム、ファイル装置、PC等への適用が考えられている。 |
|
|
|
|
|