ブレークスルーが必要な要素技術について
超高速計算機システムを実現するために、技術的なブレークスルーが必要で、特に重点的に研究開発が必要なハードウェアの要素技術について、以下のような項目が挙げられた。
なお、以下のハードウェア要素技術向上の効果を最大限に発揮するためには、ハードウェアシステム全体のバランスを十分に考慮したアーキテクチャが重要であり、アプリケーション、アルゴリズム及びハードウェアシステム相互間の相性の良さも不可欠である。
CPUの高速化
半導体微細加工技術が進むなか、リーク電流※により消費電力が増大し、結果としてCPUの高速化が阻害されると予測されている。
 |
 |
 |
 |
|
| ※ |
リーク電流 |
: |
半導体が動作していない場合でも不要に流れてしまう電流。
半導体の微細化が進むほど、大きくなる傾向にある。 |
|
|
|
 |
|
 |
この問題を解消するために必要なブレークスルーとして、消費電力を増加させないデバイス高速化手法の開発や、冷却能力の向上等が挙げられた。
また、数百ギガフロップスの単体CPU性能を実現するためには、プロセッサに関するハイレベルなアーキテクチャの検討が必要である。
これらの技術の波及効果として、高性能サーバ、ネットワーク機器、画像処理システム、PC、デジタル家電等への適用が考えられている。
CPU−メモリ間伝送速度の高速化
既存の電気伝送技術では、CPU−メモリ間伝送速度は、多信号、数十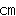 程度の伝送では5〜10ギガ 程度の伝送では5〜10ギガ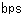 程度が高速化の限界であるとされている。 程度が高速化の限界であるとされている。
この問題を解消するために必要なブレークスルーとして、光伝送技術の開発等が挙げられた。
この技術の波及効果として、高性能サーバ、ネットワーク機器、画像処理システム、ファイル装置、PC、デジタル家電、医療機器、自動車/航空機用機器等への適用が考えられている。
ノード間伝送速度の高速化
超高速計算機システムの実現には、多数のノードを接続する大規模並列システムが不可欠であり、システム全体の実効性能向上には、更なるノード間伝送速度の向上が必要であるとされている。
要求性能を実現するために必要なブレークスルーとして、光多重伝送技術の開発や高速スイッチ技術の開発等が挙げられた。
また、システムの高速化のためには、CPU性能とノード間伝送速度のバランスが大事であるとの意見があった。
これらの技術の波及効果として、高性能サーバ、ネットワーク機器、医療機器等への適用が考えられている。
低消費電力化・冷却技術の向上
リーク電流による消費電力増大などにより、既存技術の延長では、1CPUあたり500 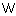 程度の高消費電力になるとされている。
この問題を解消するために必要なブレークスルーとして、リーク電流を低減するための低消費電力化技術の開発等が挙げられた。
特にこの関連では、日本の独自性・優位性を打ち出しやすい設計・技術(例えば、ロジックインメモリ※、不揮発性ロジック※、動的再構成※など)と連携させて開発を進めることも 一案としてはある。
また、CPUあたりの低消費電力化と共に、メモリの低消費電力化や、既存の空冷技術に代わる液冷を採用した小型冷却技術の開発が必要である。
これらの技術の波及効果として、高性能サーバ、ネットワーク機器、画像処理システム、ファイル装置、PC等への適用が考えられている。
|
|
|
|
|
| ※ |
| ロジックインメモリ |
: |
演算機能や論理機能をメモリ内に分散させることで,データ転送ボトルネックを解消するVLSIアーキテクチャの一つ |
| 不揮発性ロジック |
: |
不揮発性メモリ機能と演算機能をコンパクトに一体化し,ロジックインメモリ構造を実現する技術。電源off状態でも回路の状態が保持されるため,低消費電力化に有用 |
| 動的再構成 |
: |
論理回路の構成をオンラインで変更できる仕組みを持った計算機アーキテクチャの一つ |
|
|
|
|
|
|
|
|