![]()
「検索エンジン」は、インターネット上の情報の所在を検索する手段として、現在幅広く一般に用いられている。その仕組みを要約すると、自動的なプログラム(「クローラー」と呼ばれる)によって、インターネット上のウェブサイトの情報を間断なく収集し、そのデータをサーバに格納して、これを解析したものをデータベース化するとともに、利用者からの検索要求に応じてそのウェブサイトの所在等の情報を検索結果として表示するものということができる。
これらの検索エンジンにおいて行われる行為は、格納あるいは表示される情報が著作物である場合、著作権の対象となるものであり、著作権法上の問題があるのではないか、との指摘がなされているが、その一方で、インターネット上に存在する膨大な著作物が自動的に検索対象となるため、権利者から逐一許諾をとることは現実的に不可能な状況にあるなど、検索エンジンによって検索サービスを提供する者(検索エンジンサービス提供者)の法的地位の安定性が確保されていないとの懸念が指摘されている(注1)。
他方で、検索エンジンは、利用者にとっては、インターネット上に無数に存在するウェブサイトの中から求める情報の所在を容易に探索する手段として必要不可欠なものであるとともに、インターネット上の情報の提供者にとっては、より多くの人にその存在を知らせる手段として有効に活用されているなど、いわば、デジタル・ネットワーク社会におけるインフラとして、ネットワーク上における知的創造サイクルの活性化に大きな役割を果たしている(注2)。
以上を踏まえれば、権利者の私権との調和に十分に留意しつつ、検索エンジンサービス提供者の法的地位の安定性確保に資する法制度のあり方を検討する必要性が生じている。
検索エンジンサービスの提供に至る作業工程は、検索エンジンサービス提供者によって細かな差異はあるものの、概ね以下の3つに類型化できる(図参照)。
なお、検索エンジンサービスには、ロボット型及びディレクトリ型と呼ばれるものが存在する。ロボット型とは、上記一連の工程を概ねソフトウェア処理によって自動的に行うものを指し、ディレクトリ型とは、上記のうち(1)(2)の工程を人手によって行うものの通称を言うが、検索エンジンサービスは、現在ではロボット型が大勢を占めており、この傾向は今後も変わらないようであるので、以下では、ロボット型を対象として検討を行う(後述2−2(1)![]() 参照)。
参照)。
【検索エンジンサービスの提供に至る作業工程】
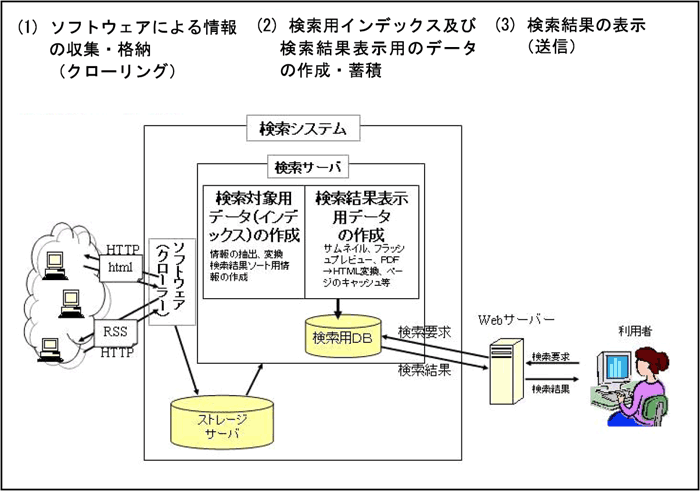
検索ロボット(クローラー)と呼ばれるソフトウェアによって、ウェブサイト情報を収集し、そのデータをストレージサーバへ格納(蓄積)する工程である。
クローラーは、訪れたウェブサイトの情報を解析し、そこに含まれるリンクをたどることにより、次々にウェブサイト情報のデータを収集するという動作を繰り返す。これにより世界中のウェブサイトを訪れ、訪れた先が新たなウェブサイトである場合は、そこから取得したデータをストレージサーバに格納する。
このようなクローラーが行う収集・格納の行為は、ある一定の時間間隔をおいて繰り返し行われ(注3)、訪れたウェブサイトの情報が更新されている場合は、ストレージサーバに格納したデータも更新される。一方、クローラーが訪れようとしたウェブサイトが、削除等によりもはや存在していない場合は、ストレージサーバ中の当該ウェブサイトに対応するデータは削除されることとなる。
ところで、このクローラーに対しては、ウェブサイト開設者に自身のウェブサイト情報が収集されないようにする方法が用意されている。具体的には、ウェブサイト開設者は、クローリングが行われないようにするための標準プロトコル(注4)を自身のウェブサイトに設定することで、技術的にクローリングを回避することが可能となる。
(1)でストレージサーバに格納されたデータを用いて、予め検索用インデックス及び検索結果表示用データを作成・蓄積する工程である。
検索効率の向上のために、ストレージサーバに格納されたウェブサイト情報のデータを解析することにより、検索用インデックスを作成し、蓄積する工程である。
解析されるデータがテキスト情報である場合、形態素解析やN-gram方式(注5)により、単語や文字を検索用インデックスとして抽出する。また、解析されるデータが動画や音楽などの情報である場合は、当該データが存在するウェブサイトにおけるウェブページ上の文字データ等を検索用インデックスとして抽出する。
様々な検索用インデックスを用意することにより、文字検索にとどまらず画像検索等の多様な検索要求に対応できることとなる。
ストレージサーバに格納されたウェブサイト情報のデータの解析によって、利用者からの検索要求に対する検索結果として表示するためのデータを作成・蓄積する工程である。これにより、検索結果を迅速に表示することができる。
検索結果表示用データは、オリジナルのウェブサイトの内容を紹介することを目的として提供されるものであり、通常、オリジナルのウェブサイトへのリンク(URL等のウェブページの所在情報)と共に提供される。なお、オリジナルのウェブサイトが削除された場合は、検索結果表示用データも順次削除され、検索結果として表示されないようになる。
代表的な検索結果表示用データは、以下のとおりである。
【検索結果表示用データの代表例】(注6)
| スニペット | 検索対象のテキストの数行の抜粋 |
|---|---|
| サムネイル | 「親指の爪(thumbnail)」に由来した語であり、縮小された画像を意味する。オリジナルの画像ファイルのサイズを小さくし、解像度を落としている。ウェブページそのもののイメージを画像として提供しているものもある。 |
| プレビュー | 動画の数シーンを切り出し、2、3秒の間表示する。 |
| キャッシュ・リンク | ウェブページのアーカイブコピー。検索結果として検索エンジンが格納しているウェブページのコピー(キャッシュ)の表示を指し、オリジナルのウェブページへのリンクとともに表示される。キャッシュ・リンクは、アクセス障害等の技術的障害の発生によりオリジナルのウェブサイトへのアクセスができなくなった場合に、これに代替して表示されるものとして、あるいは検索用語をマーキングする等によってウェブページ上の知りたい情報の探知を容易にするツールとして用いられている。 |
利用者からの検索要求に対して、(2)で作成・蓄積された検索用インデックスを用いてウェブサイト情報の検索を行い、同じく(2)で作成・蓄積された検索結果表示用データを、ウェブサイトの所在情報(URL等)と共に検索結果として、利用者に送信する工程である。
利用者側では、受信した検索結果表示用データに基づいてブラウザ等に表示が行われ、当該表示に基づいて、望むウェブページへのアクセスが行われることとなる。
検索エンジンにおける著作物の利用行為に係る著作権法上の問題に関して、特別な規定を設けている諸外国の例は見られないが、著作権侵害の成否が争われた裁判例は、少なからず存在している。
米国では、検索エンジンによる著作権侵害が問われた複数の裁判例が存在している(注7)。米国著作権法においては、著作権を一般的に制限するものとして、第107条のフェアユース規定(注8)が設けられており、裁判例の多くで、フェアユースの成否が争点となっている。もちろん、事案によって争点も事実関係も異なるため、一概には言えないが、結論だけに注目すれば、フェアユースの成立が認められた裁判例が多い。また、DMCA(デジタル・ミレニアム著作権法)により新設された第512条の免責条項が適用された例も存在する。
欧州(注9)においても、著作権侵害の成否が複数判断されている。ドイツにおいては、著作権侵害を肯定した裁判例と否定した裁判例(注10)が存在し、ベルギーにおいては、侵害が肯定され、領域内での著作物の利用中止が認められている。また、アジアでは、韓国(注11)において侵害を否定する裁判例がある(注12)。
以上、国際動向を概観すれば、検索エンジンにおける著作物の利用行為に係る著作権法上の問題の解決は、専ら裁判例の蓄積によって模索されているのが現状であるということができるが、その方向性は未だ流動的である。